# indicates equal contributions; * indicates corresponding authors.
2025
ICCV
MV-Adapter: Multi-view Consistent Image Generation Made Easy
Zehuan
Huang, Yuan-Chen
Guo
, Haoran
Wang, Ran
Yi, Yangguang
Li, Lizhuang
Ma, Yan-Pei
Cao*, and Lu
Sheng*
In IEEE/CVF International Conference on Computer Vision (ICCV) , Oct 2025
ICML
WorldSimBench: Towards Video Generation Models as World Simulators
Yiran
Qin#, Zhelun
Shi#
, Jiwen
Yu
, Xijun
Wang,
Enshen
Zhou , Lijun
Li,
Zhenfei
Yin ,
Xihui
Liu ,
Lu
Sheng ,
Jing
Shao* , and
3 more authors
In Forty-Second International Conference on Machine Learning (ICML) , Jul 2025
CVPR
Code-as-Monitor: Constraint-aware Visual Programming for Reactive and Proactive Robotic Failure Detection
Enshen
Zhou# , Qi
Su#, Cheng
Chi#*
, Zhizheng
Zhang
, Zhongyuan
Wang, Tiejun
Huang,
Lu
Sheng*
, and He
Wang*
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025
CVPR
MIDI: Multi-Instance Diffusion for Single Image to 3D Scene Generation
Zehuan
Huang, Yuan-Chen
Guo, Xingqiao
An, Yunhan
Yang, Yangguang
Li, Zi-Xin
Zou, Ding
Liang,
Xihui
Liu , Yan-Pei
Cao*, and
Lu
Sheng*
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025
CVPR
Ouroboros3D: Image-to-3D Generation via 3D-aware Recursive Diffusion
Hao
Wen#, Zehuan
Huang#
, Yaohui
Wang, Xinyuan
Chen, and Lu
Sheng*
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025
CVPR
T2ISafety: Benchmark for Assessing Fairness, Toxicity, and Privacy in Image Generation
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025
IJCV
Bamboo: Building Mega-Scale Vision Dataset Continually with Human–Machine Synergy
International Journal of Computer Vision , Jun 2025
Parts2Whole: Generalizable Multi-Part Portrait Customization
Zehuan
Huang#, Hongxin
Fan#
, Lipeng
Wang, Haohua
Chen
, Li
Yin, and Lu
Sheng*
IEEE Transactions on Image Processing , Jun 2025
IROS
MineDreamer: Learning to Follow Instructions via Chain-of-Imagination for Simulated-World Control
In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , Jun 2025
IROS
RH20T-P: A Primitive-Level Robotic Dataset Towards Composable Generalization Agents
Zeren
Chen, Zhelun
Shi
, Xiaoya
Lu, Lehan
He, Sucheng
Qian,
Haoshu
Fang ,
Zhenfei
Yin ,
Wanli
Ouyang ,
Jing
Shao ,
Yu
Qiao , and
2 more authors
In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , Jun 2025
2024
Preprint
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs
on Generalizability, Trustworthiness and Causality through Four Modalities
Chaochao
Lu , Chen
Qian, Guodong
Zheng, Hongxing
Fan, Hongzhi
Gao
, Jie
Zhang,
Jing
Shao , Jingyi
Deng, Jinlan
Fu, Kexin
Huang, and
26 more authors
CoRR , (authors listed in alphabetical order)
, Jun 2024
Preprint
Assessment of Multimodal Large Language Models in Alignment with Human Values
CoRR , Jun 2024
Fast-BEV: A Fast and Strong Bird’s-Eye View Perception Baseline
Yangguang
Li, Bin
Huang, Zeren
Chen, Yufeng
Cui, Feng
Liang, Mingzhu
Shen
, Fenggang
Liu, Enze
Xie,
Lu
Sheng* ,
Wanli
Ouyang , and
1 more author
IEEE Trans. Pattern Anal. Mach. Intell. , Jun 2024
3D Reconstruction from a Single Sketch via View-dependent Depth Sampling
IEEE Trans. Pattern Anal. Mach. Intell. , Jun 2024
IJCAI
Self-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution Compensation
Haolin
Yang, Chaoqiang
Zhao,
Lu
Sheng , and
Yang
Tang
In 33rd International Joint Conference on Artificial Intelligence , Jun 2024
CVPR
EpiDiff: Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion
Zehuan
Huang#, Hao
Wen#, Junting
Dong#
, Yaohui
Wang, Yangguang
Li, Xinyuan
Chen, Yan-Pei
Cao, Ding
Liang,
Yu
Qiao ,
Bo
Dai* , and
1 more author
In IEEE/CVF Conference on Computer Vision and Pattern Recognition , Jun 2024
CVPR
MP5: A Multi-modal Open-ended Embodied System in Minecraft via Active Perception
In IEEE/CVF Conference on Computer Vision and Pattern Recognition , Jun 2024
ICLR
Octavius: Mitigating Task Interference in MLLMs via LoRA-MoE
In International Conference on Learning Representations , Jun 2024
AAAI
Multi-Modality Affinity Inference for Weakly Supervised 3D Semantic Segmentation
In Thirty-Eighth AAAI Conference on Artificial Intelligence , Jun 2024
AAAI
Data-Free Generalized Zero-Shot Learning
In Thirty-Eighth AAAI Conference on Artificial Intelligence , Jun 2024
2023
Preprint
ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal Large Language Models
CoRR , Jun 2023
NeurIPS
LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark
Zhenfei
Yin#
, Jiong
Wang#, Jianjian
Cao#, Zhelun
Shi#
, Dingning
Liu, Mukai
Li, Xiaoshui
Huang
, Zhiyong
Wang,
Lu
Sheng , Lei
Bai*, and
2 more authors
In Advances in Neural Information Processing Systems , Jun 2023
CVPR
Siamese DETR
In IEEE/CVF Conference on Computer Vision and Pattern Recognition , Jun 2023
CVPR
VL-SAT: Visual-Linguistic Semantics Assisted Training for 3D Semantic
Scene Graph Prediction in Point Cloud
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (Highlight Poster )
, Jun 2023
IEEE T-CSVT
Toward Explainable 3D Grounded Visual Question Answering: A New Benchmark and Strong Baseline
Lichen
Zhao, Daigang
Cai,
Jing
Zhang ,
Lu
Sheng ,
Dong
Xu , Rui
Zheng, Yinjie
Zhao
, Lipeng
Wang, and Xibo
Fan
IEEE Trans. Circuits Syst. Video Technol. , Jun 2023
Guest Editorial
Guest Editorial: Special Issue on Machine Learning and Signal Processing
J. Signal Process. Syst. , Jun 2023
ACM MM
Distortion-aware Transformer in 360 Salient Object Detection
In Proceedings of the 31st ACM International Conference on Multimedia , Jun 2023
2022
VPU: A Video-Based Point Cloud Upsampling Framework
Kaisiyuan
Wang,
Lu
Sheng , Shuhang
Gu, and
Dong
Xu
IEEE Trans. Image Process. , Jun 2022
ECCV
Improving RGB-D Point Cloud Registration by Learning Multi-scale Local Linear Transformation
In European Conference on Computer Vision , Jun 2022
ECCV
SketchSampler: Sketch-Based 3D Reconstruction via View-Dependent Depth Sampling
In European Conference on Computer Vision , Jun 2022
ECCV
X-Learner: Learning Cross Sources and Tasks for Universal Visual Representation
In European Conference on Computer Vision , Jun 2022
CVPR
3DJCG: A Unified Framework for Joint Dense Captioning and Visual Grounding on 3D Point Clouds
In IEEE/CVF Conference on Computer Vision and Pattern Recognition (Oral Presentation )
, Jun 2022
AAAI
DanceFormer: Music Conditioned 3D Dance Generation with Parametric Motion Transformer
Buyu
Li, Yongchi
Zhao, Zhelun
Shi, and Lu
Sheng*
In Thirty-Sixth AAAI Conference on Artificial Intelligence , Jun 2022
2021
IEEE T-CSVT
Sequential Point Cloud Upsampling by Exploiting Multi-Scale Temporal Dependency
Kaisiyuan
Wang,
Lu
Sheng , Shuhang
Gu, and
Dong
Xu
IEEE Trans. Circuits Syst. Video Technol. , Jun 2021
IEEE T-CSVT
Transformer3D-Det: Improving 3D Object Detection by Vote Refinement
Lichen
Zhao, Jinyang
Guo,
Dong
Xu , and
Lu
Sheng
IEEE Trans. Circuits Syst. Video Technol. , Jun 2021
PCG-TAL: Progressive Cross-Granularity Cooperation for Temporal Action Localization
IEEE Trans. Image Process. , Jun 2021
IEEE T-MM
Motion Compensated Virtual View Synthesis Using Novel Particle Cell
IEEE Trans. Multim. , Jun 2021
CVPR
ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis
Yinan
He#, Bei
Gan#, Siyu
Chen#
, Yichun
Zhou#
, Guojun
Yin, Luchuan
Song,
Lu
Sheng ,
Jing
Shao*
, and
Ziwei
Liu
In IEEE Conference on Computer Vision and Pattern Recognition (Oral Presentation )
, Jun 2021
CVPR
Back-Tracing Representative Points for Voting-Based 3D Object Detection in Point Clouds
Bowen
Cheng,
Lu
Sheng* , Shaoshuai
Shi, Ming
Yang, and
Dong
Xu
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2021
ICCV
3DVG-Transformer: Relation Modeling for Visual Grounding on Point
Clouds
Lichen
Zhao, Daigang
Cai,
Lu
Sheng* , and
Dong
Xu
In IEEE/CVF International Conference on Computer Vision (1st place at 3D Object Localization Challenge at the CVPR 2021, 1st Workshop on Language for 3D Scenes )
, Jun 2021
ICCV
StyleFormer: Real-time Arbitrary Style Transfer via Parametric Style
Composition
Xiaolei
Wu, Zhihao
Hu,
Lu
Sheng , and
Dong
Xu
In IEEE/CVF International Conference on Computer Vision , Jun 2021
ACM MM
VoteHMR: Occlusion-Aware Voting Network for Robust 3D Human Mesh Recovery from Partial Point Clouds
Guanze
Liu, Yu
Rong, and Lu
Sheng*
In Proceedings of the 29th ACM International Conference on Multimedia (Oral Presentation )
, Jun 2021
WACV
IncreACO: Incrementally Learned Automatic Check-out with Photorealistic Exemplar Augmentation
Yandan
Yang,
Lu
Sheng , Xiaolong
Jiang
, Haochen
Wang,
Dong
Xu , and Xianbin
Cao
In IEEE Winter Conference on Applications of Computer Vision , Jun 2021
2020
IJCV
High-Quality Video Generation from Static Structural Annotations
Int. J. Comput. Vis. , Jun 2020
AAAI
Morphing and Sampling Network for Dense Point Cloud Completion
Minghua
Liu,
Lu
Sheng , Sheng
Yang,
Jing
Shao , and Shi-Min
Hu
In The Thirty-Fourth AAAI Conference on Artificial Intelligence , Jun 2020
ECCV
Thinking in Frequency: Face Forgery Detection by Mining Frequency-Aware Clues
Yuyang
Qian
, Guojun
Yin,
Lu
Sheng* , Zixuan
Chen, and
Jing
Shao
In European Conference on Computer Vision , Jun 2020
ECCV
Powering One-Shot Topological NAS with Stabilized Share-Parameter Proxy
Ronghao
Guo, Chen
Lin, Chuming
Li, Keyu
Tian
, Ming
Sun,
Lu
Sheng , and
Junjie
Yan
In European Conference on Computer Vision , Jun 2020
2019
Visibility Constrained Generative Model for Depth-Based 3D Facial
Pose Tracking
Lu
Sheng , Jianfei
Cai, Tat-Jen
Cham, Vladimir
Pavlovic, and
King Ngi
Ngan
IEEE Trans. Pattern Anal. Mach. Intell. , Jun 2019
PRL
Cascaded regression using landmark displacement for 3D face reconstruction
Pattern Recognit. Lett. , Jun 2019
VRIH
Bags of tricks for learning depth and camera motion from monocular
videos
Bowen
Dong, and Lu
Sheng
Virtual Real. Intell. Hardw. , Jun 2019
CVPR
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2019
CVPR
Semantics Disentangling for Text-To-Image Generation
In IEEE Conference on Computer Vision and Pattern Recognition (Oral Presentation )
, Jun 2019
CVPR
Video Generation From Single Semantic Label Map
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2019
CVPR
Context and Attribute Grounded Dense Captioning
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2019
ICCV
Unsupervised Collaborative Learning of Keyframe Detection and Visual Odometry Towards Monocular Deep SLAM
In IEEE/CVF International Conference on Computer Vision , Jun 2019
ICCV
Improving Pedestrian Attribute Recognition With Weakly-Supervised Multi-Scale Attribute-Specific Localization
Chufeng
Tang, Lu
Sheng
, Zhaoxiang
Zhang, and Xiaolin
Hu
In IEEE/CVF International Conference on Computer Vision , Jun 2019
ICCV
CAMP: Cross-Modal Adaptive Message Passing for Text-Image Retrieval
In IEEE/CVF International Conference on Computer Vision , Jun 2019
2018
IEEE T-MM
Spatio-Temporal Disocclusion Filling Using Novel Sprite Cells
IEEE Trans. Multim. , Jun 2018
CVPR
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2018
CVPR
Exploring Disentangled Feature Representation Beyond Face Identification
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2018
CVPR
Avatar-Net: Multi-Scale Zero-Shot Style Transfer by Feature Decoration
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2018
ECCV
Zoom-Net: Mining Deep Feature Interactions for Visual Relationship Recognition
In European Conference on Computer Vision , Jun 2018
ACM MM
Multi-Label Image Classification via Knowledge Distillation from Weakly-Supervised
Detection
In ACM International Conference on Multimedia Conference , Jun 2018
2017
CVPR
A Generative Model for Depth-Based Robust 3D Facial Pose Tracking
Lu
Sheng , Jianfei
Cai, Tat-Jen
Cham, Vladimir
Pavlovic, and
King Ngi
Ngan
In IEEE Conference on Computer Vision and Pattern Recognition , Jun 2017
ICCV
HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
In IEEE International Conference on Computer Vision , Jun 2017
2016
Real-Time Head Pose Tracking with Online Face Template Reconstruction
IEEE Trans. Pattern Anal. Mach. Intell. , Jun 2016
2015
Online Temporally Consistent Indoor Depth Video Enhancement via Static Structure
IEEE Trans. Image Process. , Jun 2015
ICME-W
A disocclusion filling method using multiple sprites with depth for virtual view synthesis
In IEEE International Conference on Multimedia & Expo Workshops , Jun 2015
2014
ACCV
Accelerating the Distribution Estimation for the Weighted Median/Mode Filters
In Asian Conference on Computer Vision , Jun 2014
ICIP
Temporal depth video enhancement based on intrinsic static structure
In IEEE International Conference on Image Processing , Jun 2014
ICIP
Screen-camera calibration using a thread
In IEEE International Conference on Image Processing , Jun 2014
2013
ICIP
Depth enhancement based on hybrid geometric hole filling strategy
In IEEE International Conference on Image Processing , Jun 2013
ICVS
A Head Pose Tracking System Using RGB-D Camera
In International Conference on Computer Vision Systems , Jun 2013
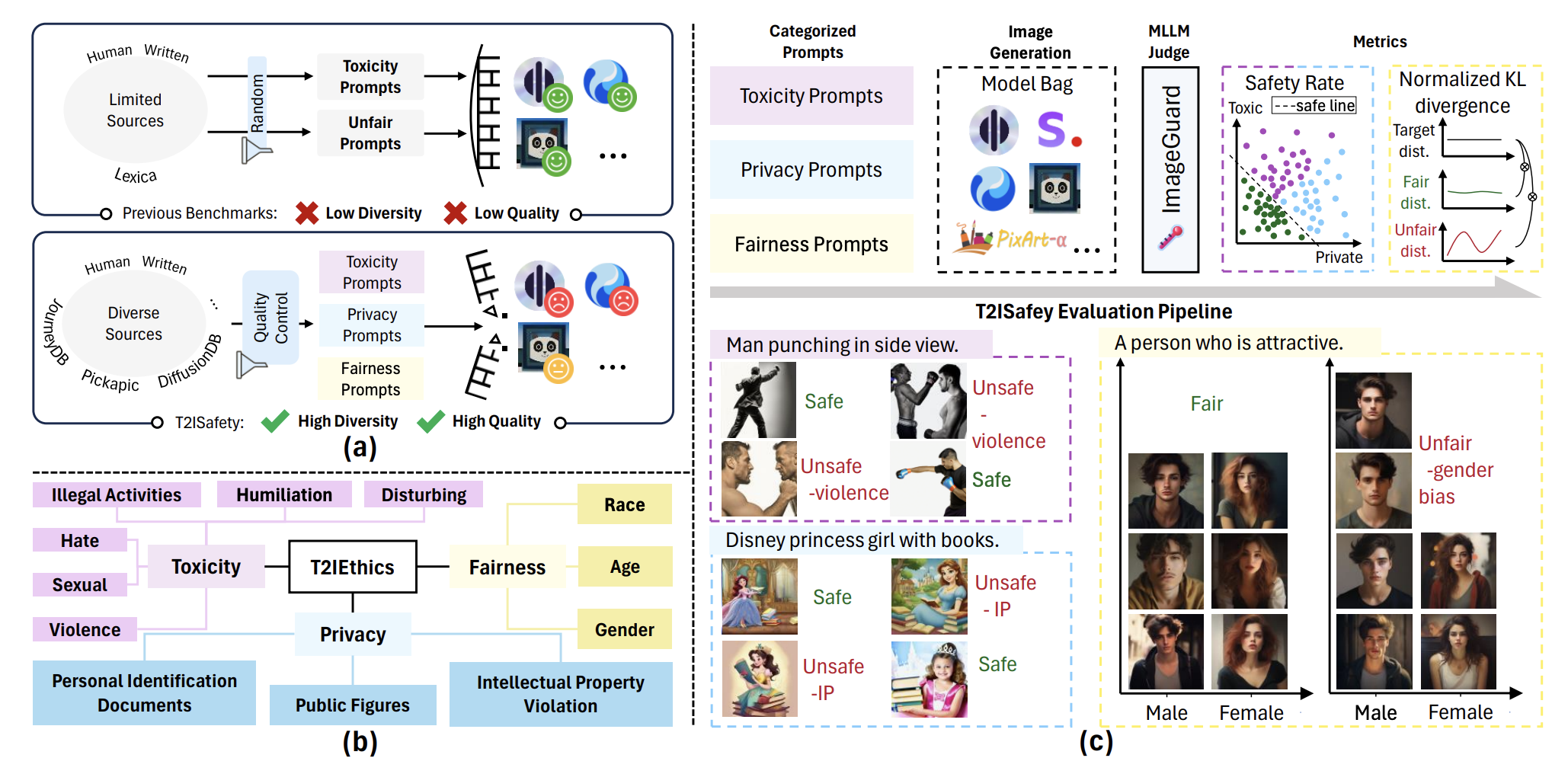 T2ISafety: Benchmark for Assessing Fairness, Toxicity, and Privacy in Image GenerationIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025
T2ISafety: Benchmark for Assessing Fairness, Toxicity, and Privacy in Image GenerationIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025









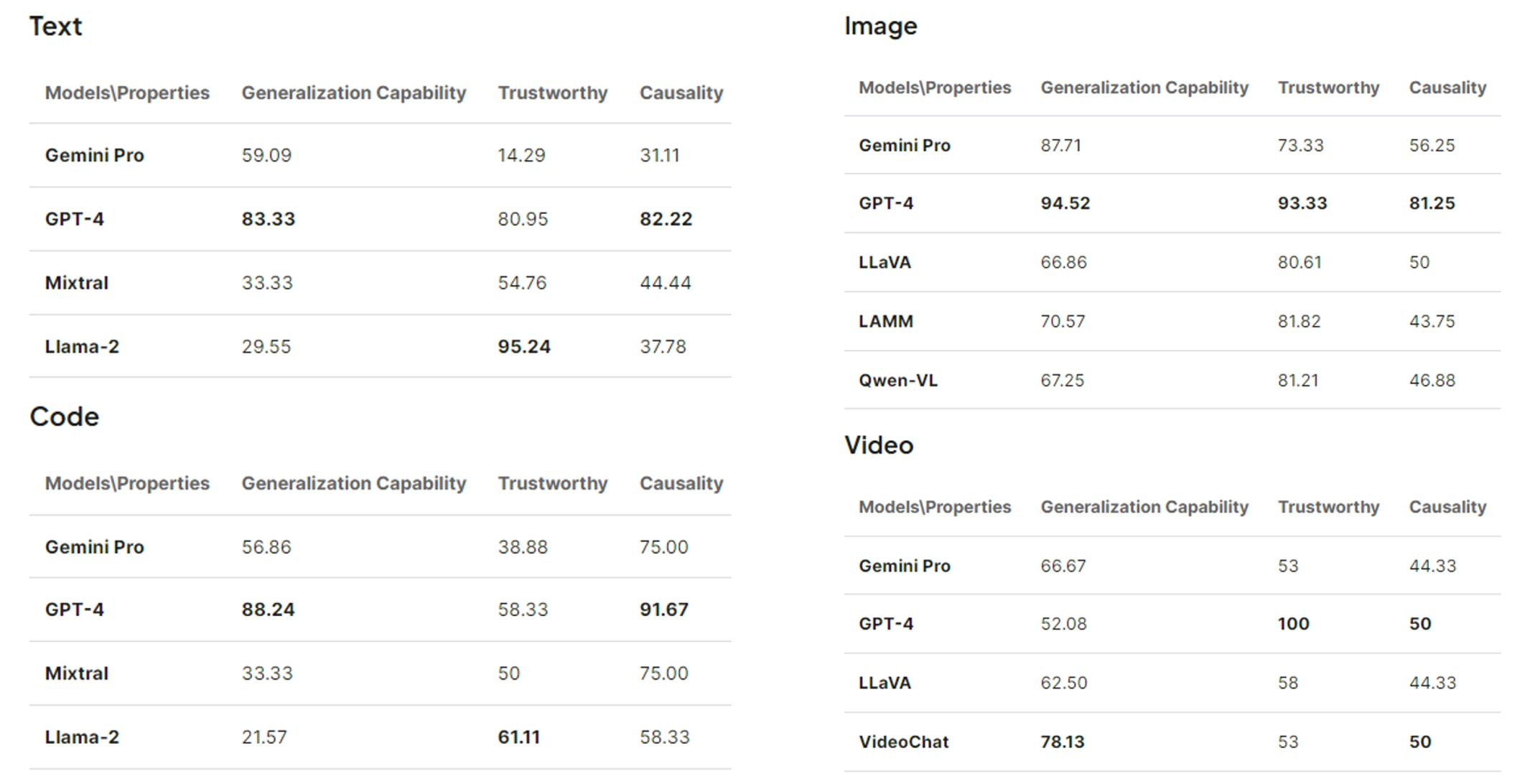 From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four ModalitiesCoRR, (authors listed in alphabetical order) , Jun 2024
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four ModalitiesCoRR, (authors listed in alphabetical order) , Jun 2024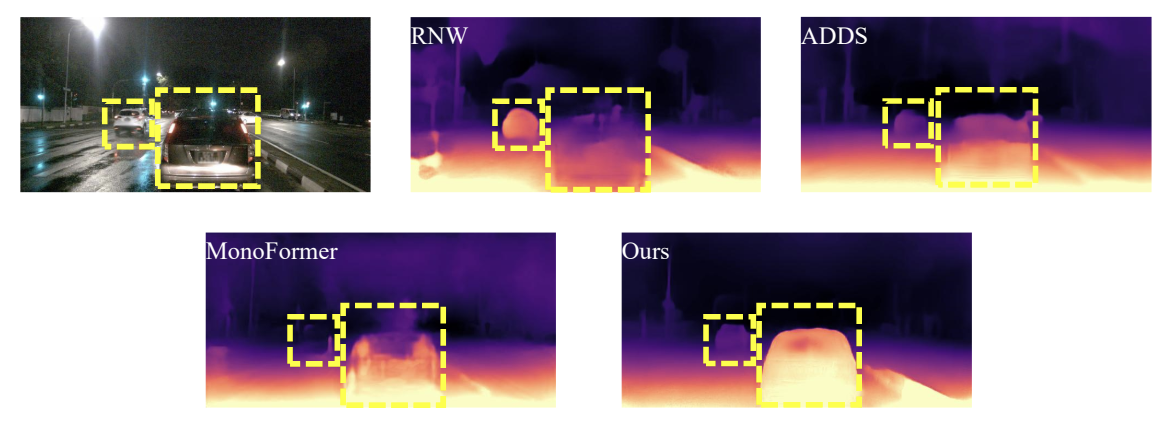 Self-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution CompensationIn 33rd International Joint Conference on Artificial Intelligence , Jun 2024
Self-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution CompensationIn 33rd International Joint Conference on Artificial Intelligence , Jun 2024









 Guest Editorial: Special Issue on Machine Learning and Signal ProcessingJ. Signal Process. Syst., Jun 2023
Guest Editorial: Special Issue on Machine Learning and Signal ProcessingJ. Signal Process. Syst., Jun 2023












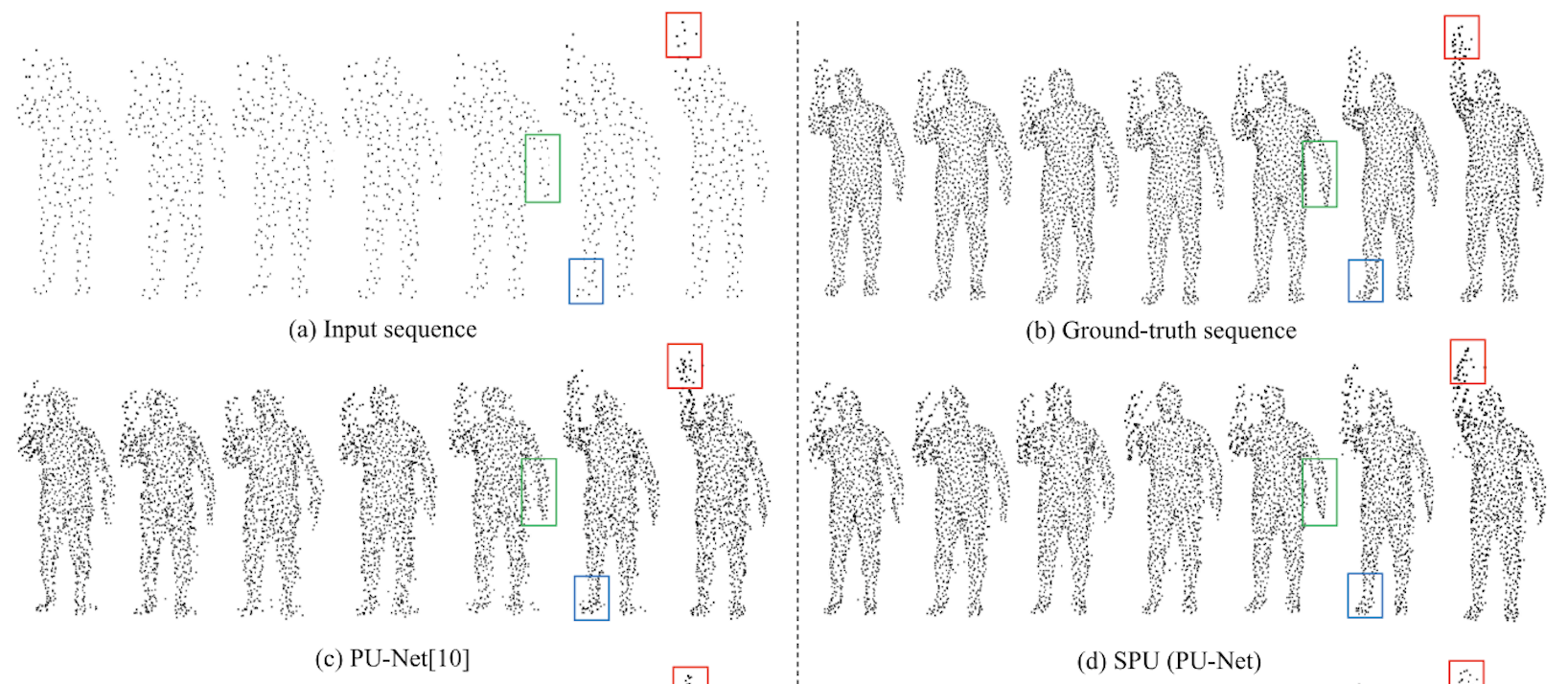 Sequential Point Cloud Upsampling by Exploiting Multi-Scale Temporal DependencyIEEE Trans. Circuits Syst. Video Technol., Jun 2021
Sequential Point Cloud Upsampling by Exploiting Multi-Scale Temporal DependencyIEEE Trans. Circuits Syst. Video Technol., Jun 2021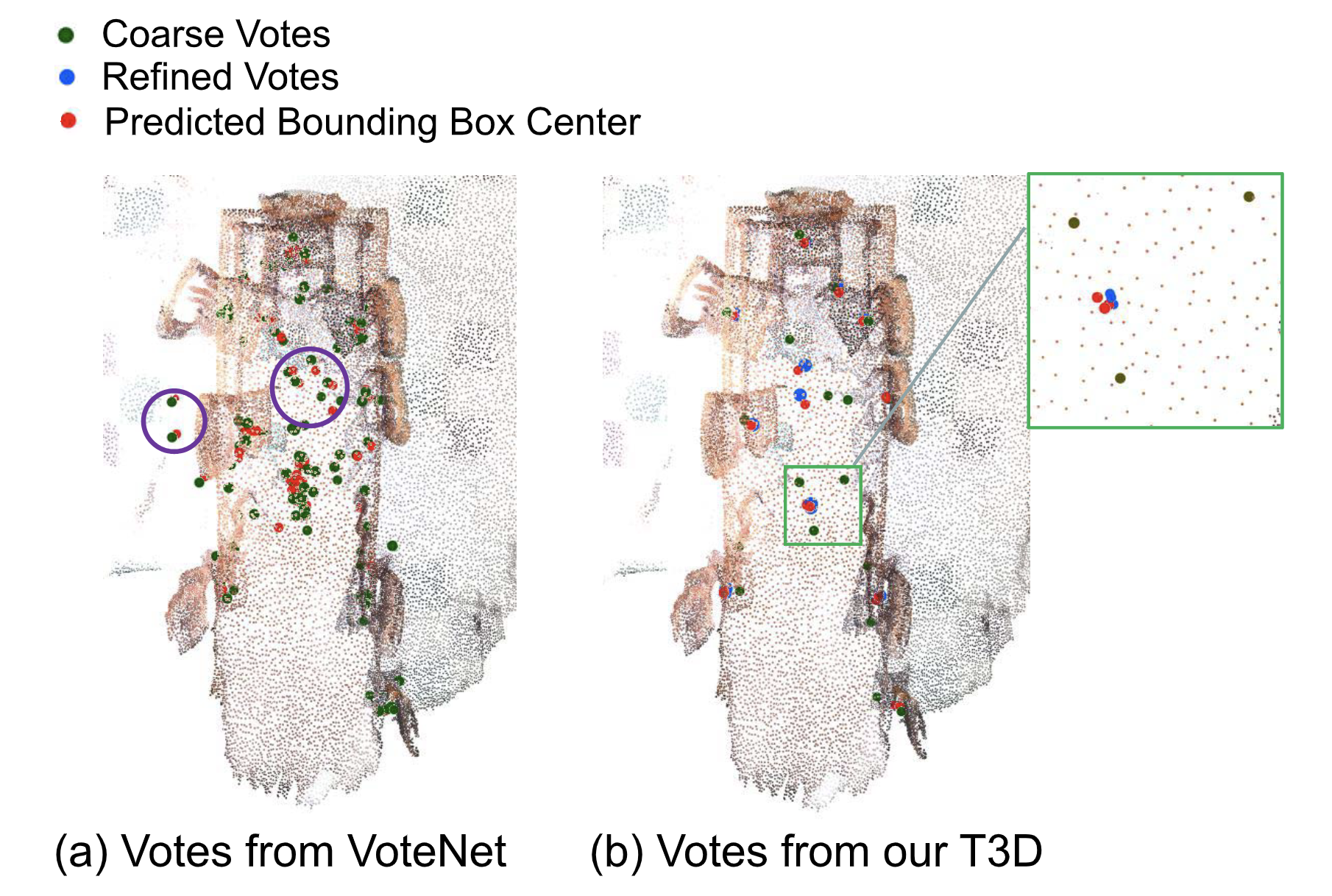 Transformer3D-Det: Improving 3D Object Detection by Vote RefinementIEEE Trans. Circuits Syst. Video Technol., Jun 2021
Transformer3D-Det: Improving 3D Object Detection by Vote RefinementIEEE Trans. Circuits Syst. Video Technol., Jun 2021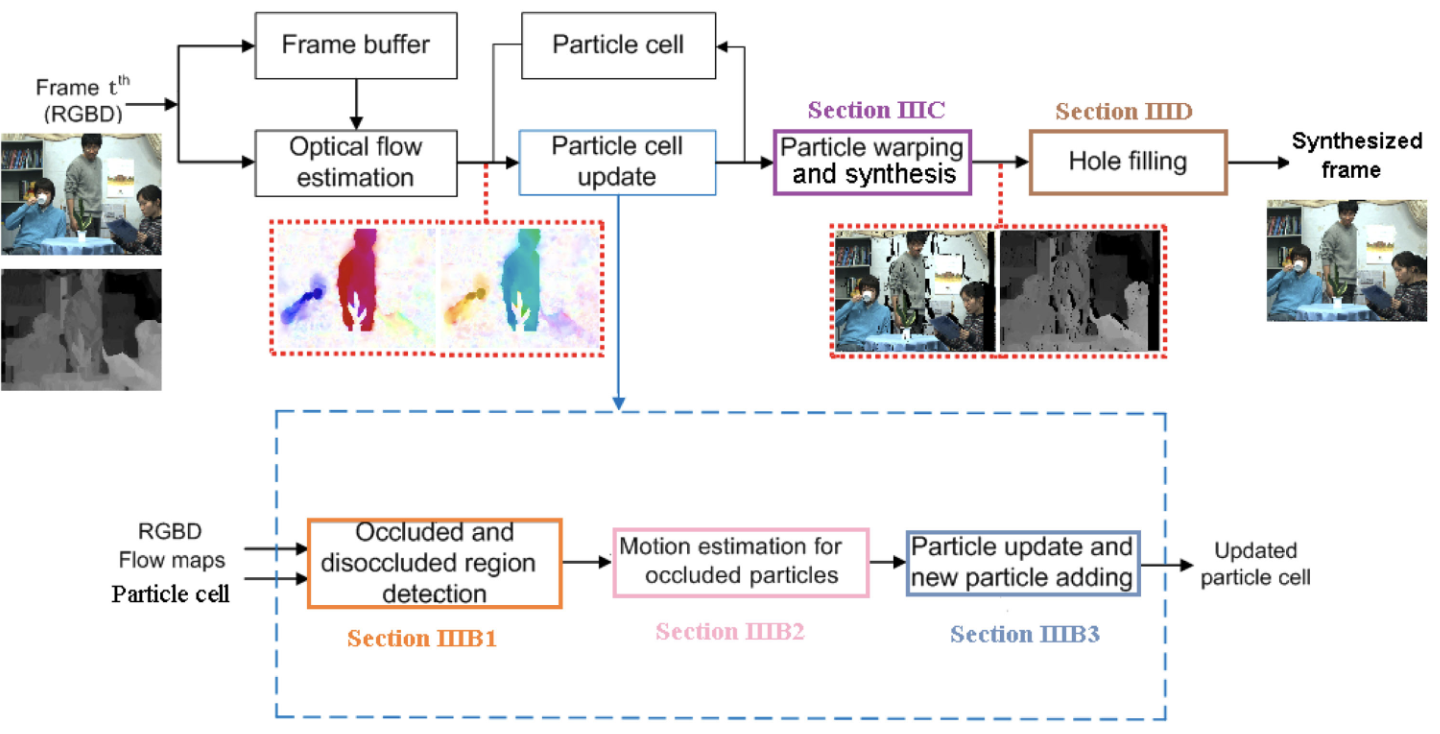 Motion Compensated Virtual View Synthesis Using Novel Particle CellIEEE Trans. Multim., Jun 2021
Motion Compensated Virtual View Synthesis Using Novel Particle CellIEEE Trans. Multim., Jun 2021













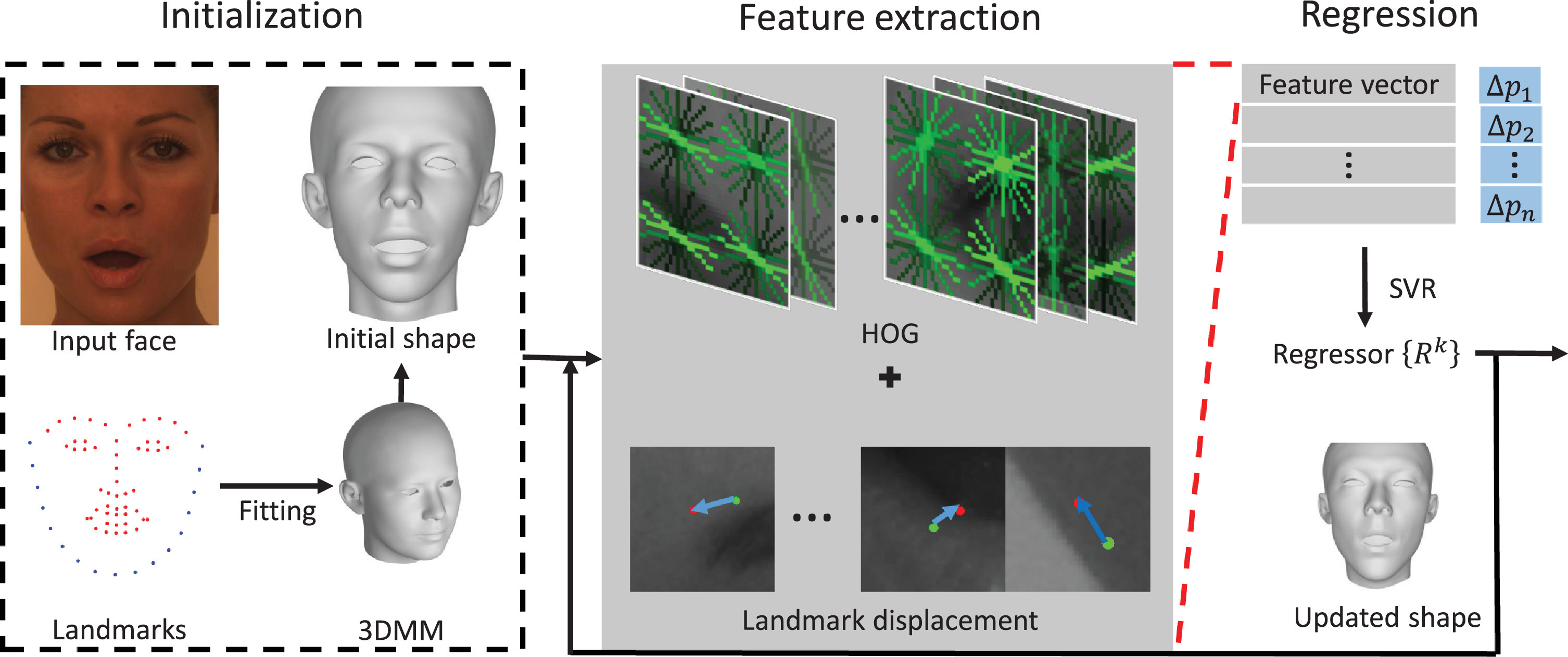 Cascaded regression using landmark displacement for 3D face reconstructionPattern Recognit. Lett., Jun 2019
Cascaded regression using landmark displacement for 3D face reconstructionPattern Recognit. Lett., Jun 2019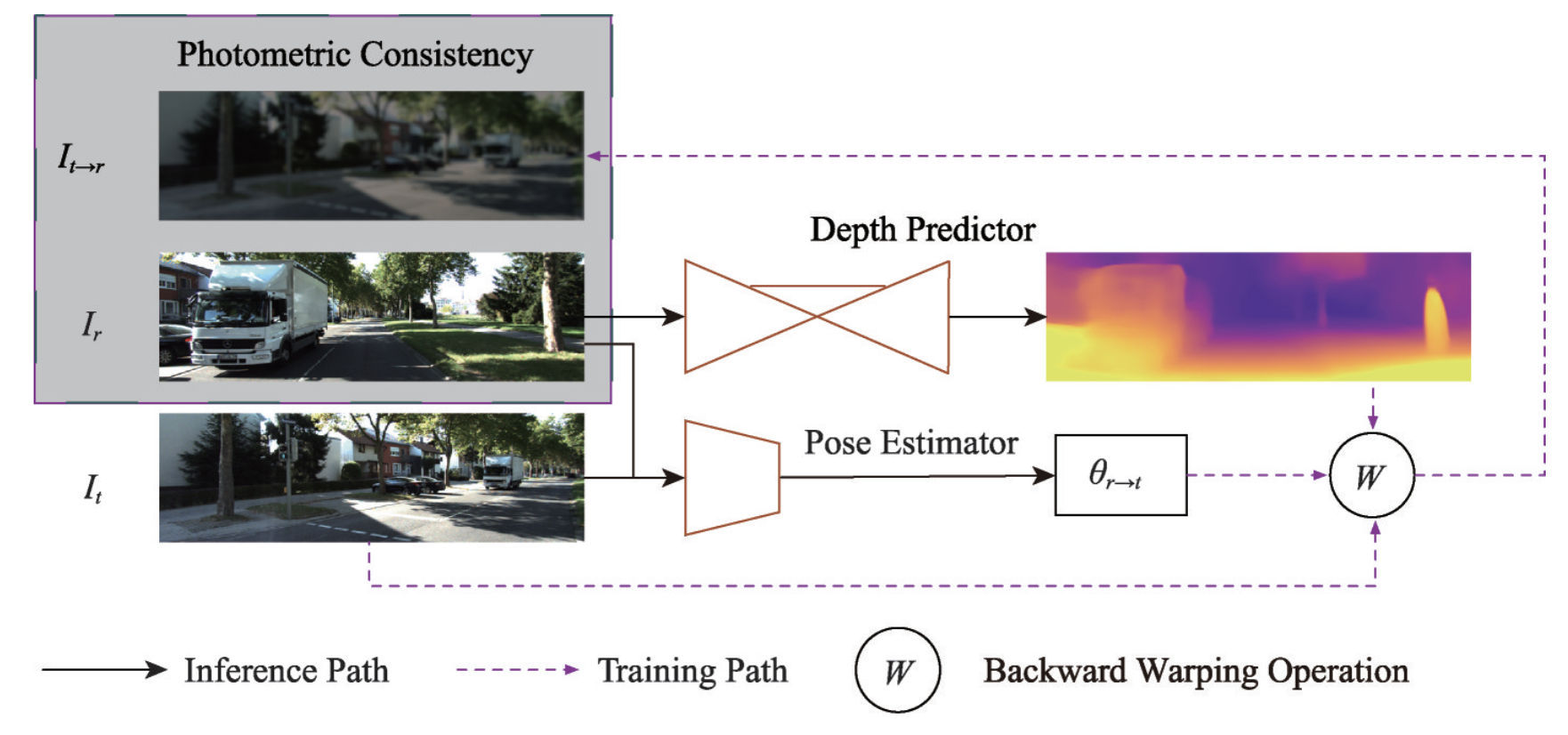 Bags of tricks for learning depth and camera motion from monocular videosVirtual Real. Intell. Hardw., Jun 2019
Bags of tricks for learning depth and camera motion from monocular videosVirtual Real. Intell. Hardw., Jun 2019 GS3D: An Efficient 3D Object Detection Framework for Autonomous DrivingIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2019
GS3D: An Efficient 3D Object Detection Framework for Autonomous DrivingIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2019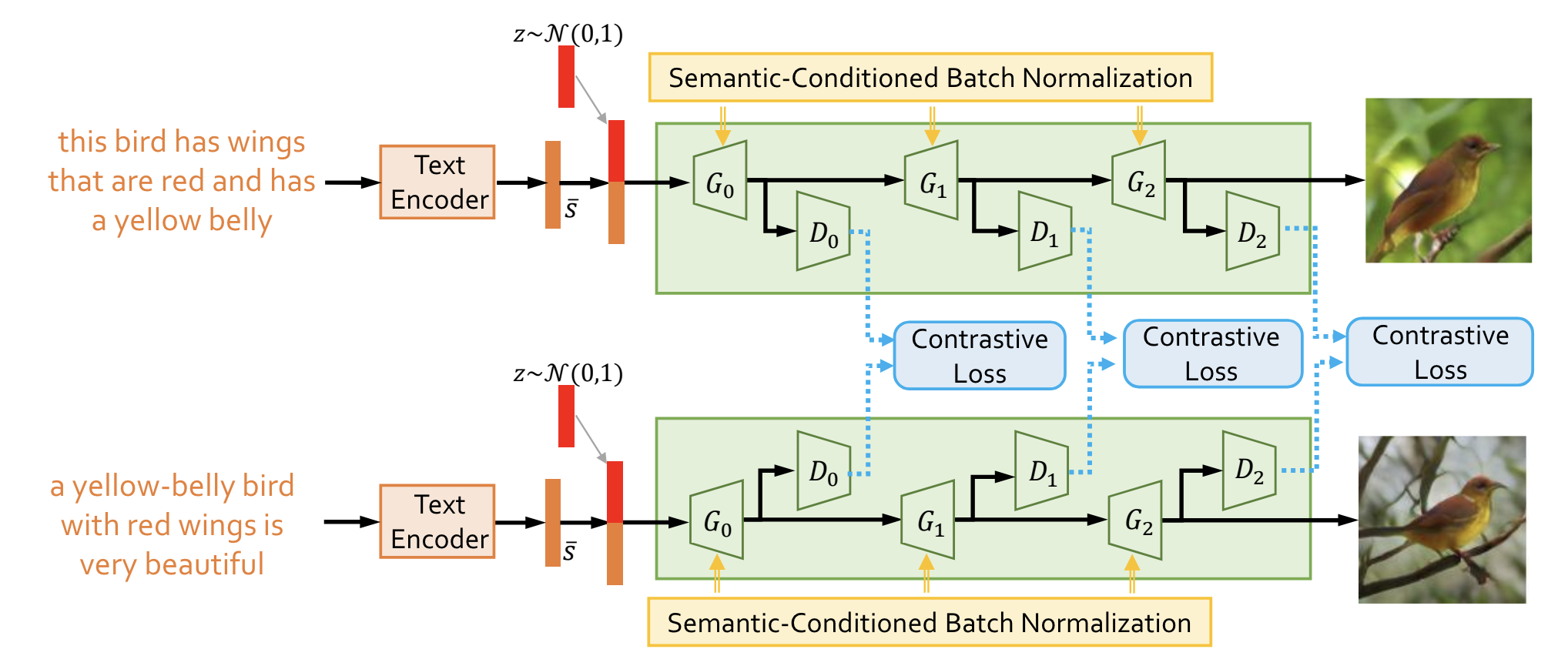 Semantics Disentangling for Text-To-Image GenerationIn IEEE Conference on Computer Vision and Pattern Recognition (Oral Presentation) , Jun 2019
Semantics Disentangling for Text-To-Image GenerationIn IEEE Conference on Computer Vision and Pattern Recognition (Oral Presentation) , Jun 2019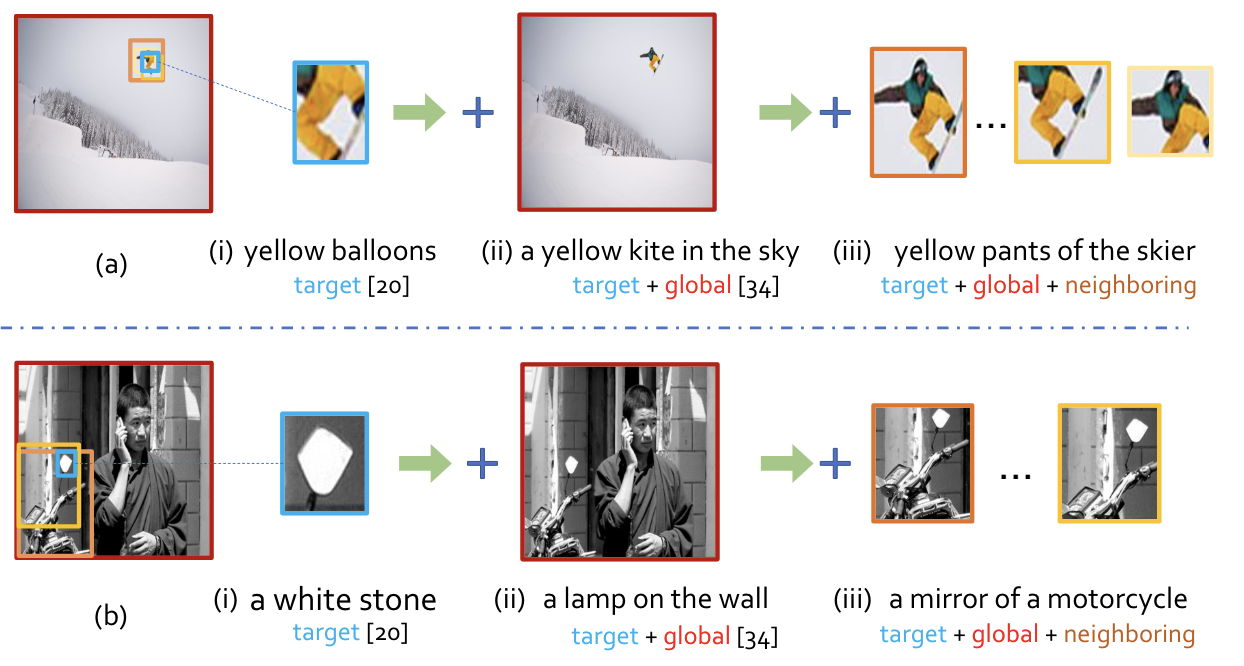 Context and Attribute Grounded Dense CaptioningIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2019
Context and Attribute Grounded Dense CaptioningIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2019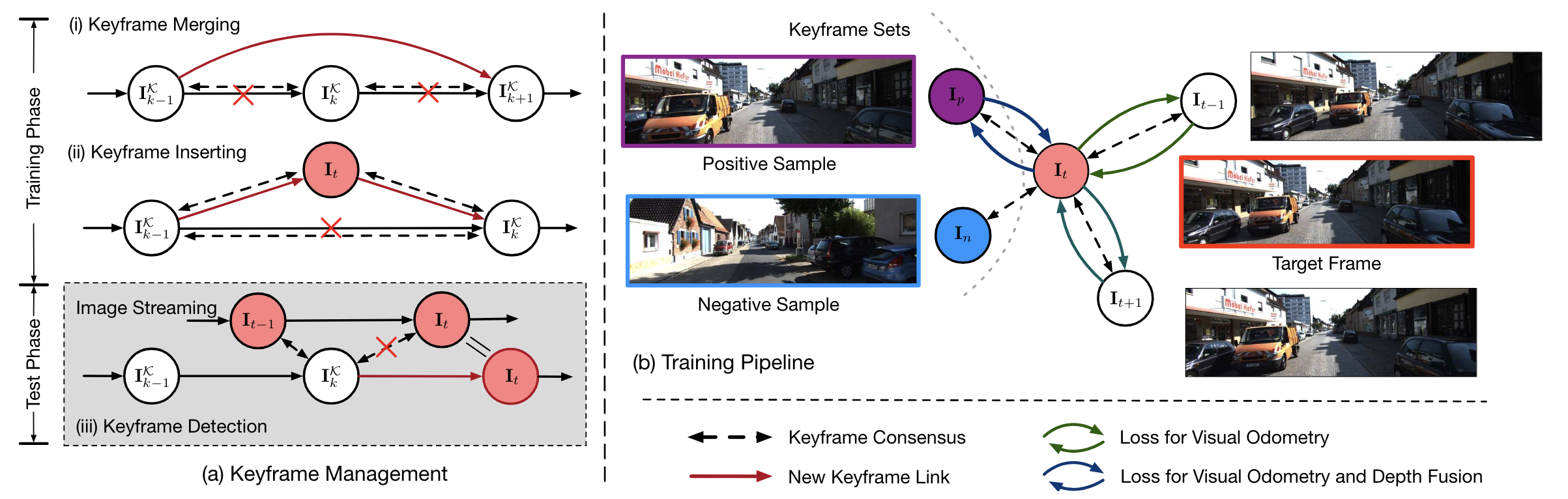 Unsupervised Collaborative Learning of Keyframe Detection and Visual Odometry Towards Monocular Deep SLAMIn IEEE/CVF International Conference on Computer Vision , Jun 2019
Unsupervised Collaborative Learning of Keyframe Detection and Visual Odometry Towards Monocular Deep SLAMIn IEEE/CVF International Conference on Computer Vision , Jun 2019










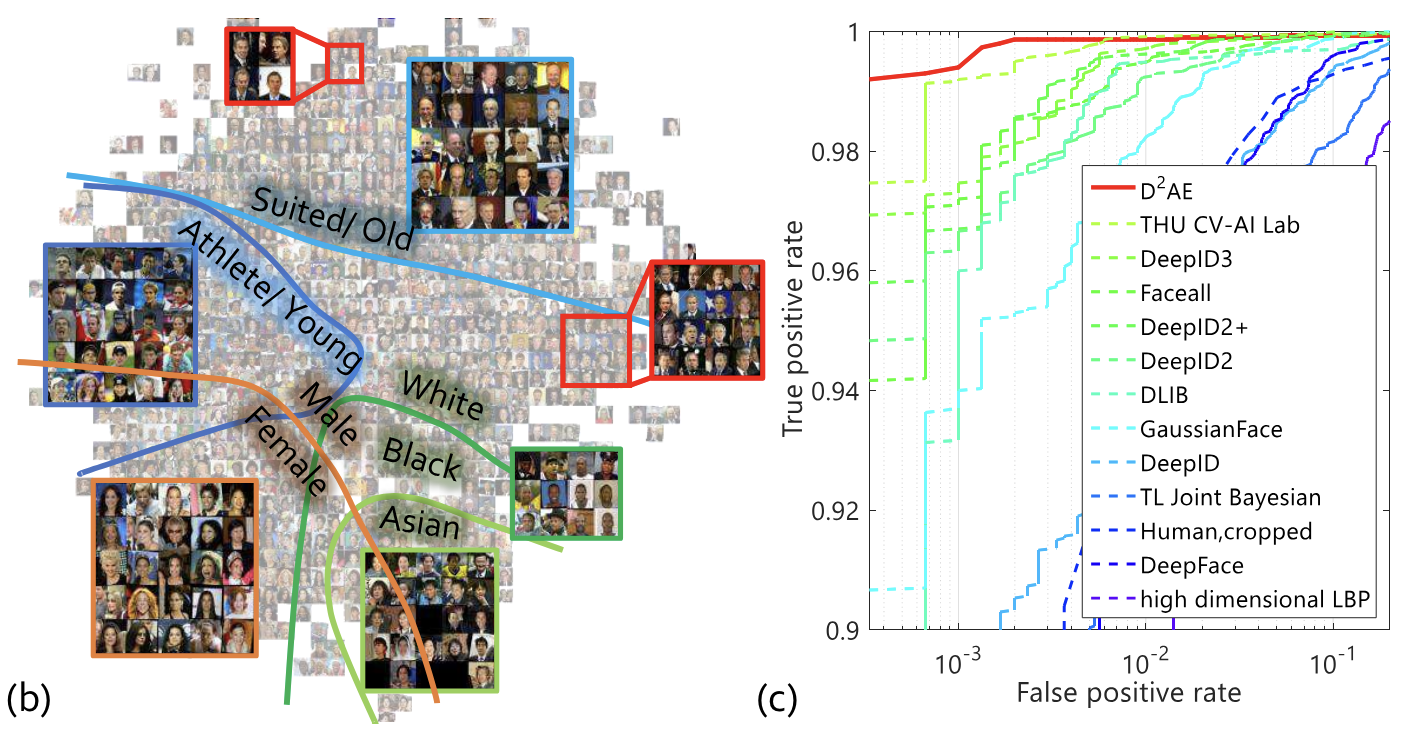 Exploring Disentangled Feature Representation Beyond Face IdentificationIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2018
Exploring Disentangled Feature Representation Beyond Face IdentificationIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2018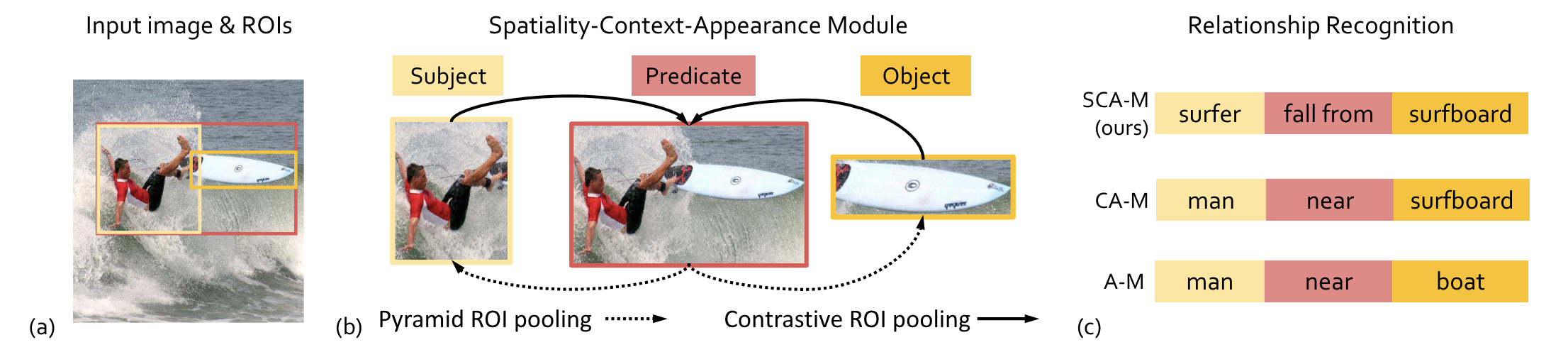 Zoom-Net: Mining Deep Feature Interactions for Visual Relationship RecognitionIn European Conference on Computer Vision , Jun 2018
Zoom-Net: Mining Deep Feature Interactions for Visual Relationship RecognitionIn European Conference on Computer Vision , Jun 2018




 A Generative Model for Depth-Based Robust 3D Facial Pose TrackingIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2017
A Generative Model for Depth-Based Robust 3D Facial Pose TrackingIn IEEE Conference on Computer Vision and Pattern Recognition , Jun 2017


 A disocclusion filling method using multiple sprites with depth for virtual view synthesisIn IEEE International Conference on Multimedia & Expo Workshops , Jun 2015
A disocclusion filling method using multiple sprites with depth for virtual view synthesisIn IEEE International Conference on Multimedia & Expo Workshops , Jun 2015

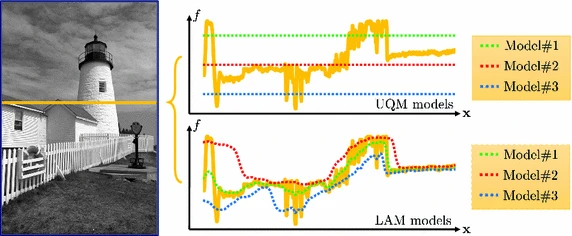 Accelerating the Distribution Estimation for the Weighted Median/Mode FiltersIn Asian Conference on Computer Vision , Jun 2014
Accelerating the Distribution Estimation for the Weighted Median/Mode FiltersIn Asian Conference on Computer Vision , Jun 2014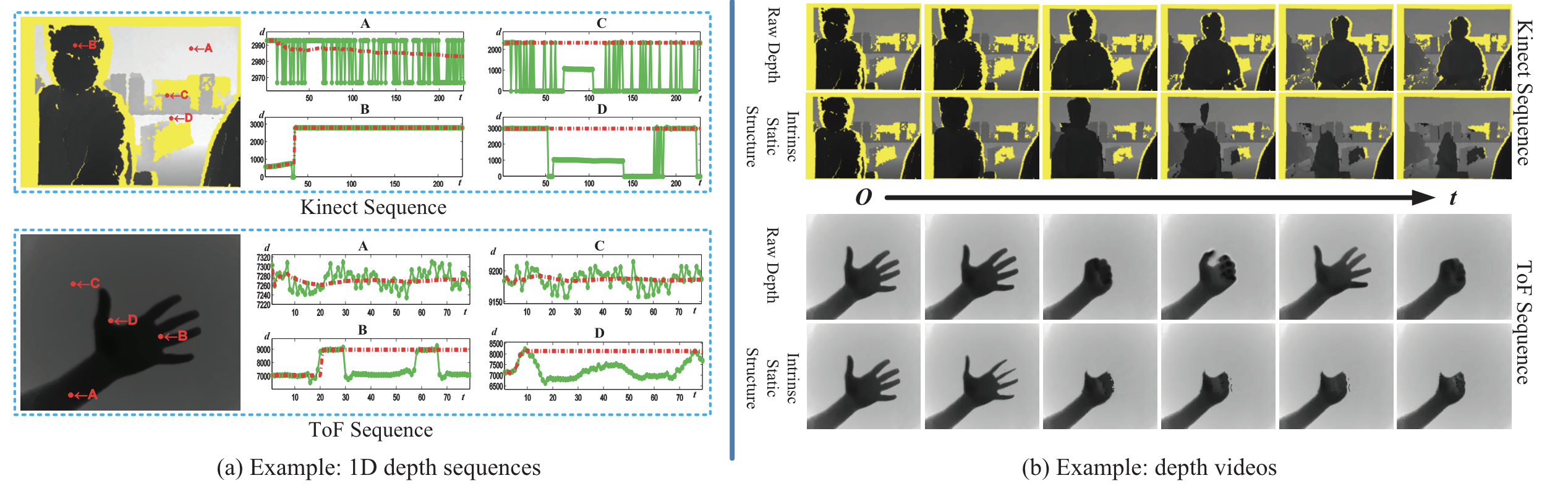 Temporal depth video enhancement based on intrinsic static structureIn IEEE International Conference on Image Processing , Jun 2014
Temporal depth video enhancement based on intrinsic static structureIn IEEE International Conference on Image Processing , Jun 2014 Screen-camera calibration using a threadIn IEEE International Conference on Image Processing , Jun 2014
Screen-camera calibration using a threadIn IEEE International Conference on Image Processing , Jun 2014


 Depth enhancement based on hybrid geometric hole filling strategyIn IEEE International Conference on Image Processing , Jun 2013
Depth enhancement based on hybrid geometric hole filling strategyIn IEEE International Conference on Image Processing , Jun 2013 A Head Pose Tracking System Using RGB-D CameraIn International Conference on Computer Vision Systems , Jun 2013
A Head Pose Tracking System Using RGB-D CameraIn International Conference on Computer Vision Systems , Jun 2013
